Increasing Reusability of Components
Overview
Qarbine promotes component reuse in the same manner code libraries are used. We do not want to redundantly define things that lead to sprawl. This quickly becomes a development, maintenance, and QA nightmare. For example, while analysis templates may embed data queries, best practice would instead suggest to define that data query in a Data Source and reference that component from your analysis template.
Managing Component Access
Components should be stored in folders that have meaningful names and are visible to appropriate team members. The Qarbine administrator can set up folders so that these components are only runnable or viewable and runnable. Alternatively, edit permission may be granted as well at the folder level.
In addition, component editors may set “non-owner” policies to control who may see them as well. Folder level permissions are considered first and then the “non-owner” policy applied.
Data Sources
The segregation of data retrieval from data formatting enables the retrieval component to be defined by team members skilled in database access and then efficiently discovered and reused by others. This avoids query sprawl.
To further improve reusability the queries may include variable placeholders. The values may be obtained through Prompt components, programmatically passed in, or through Qarbine initiated dialogs. Below is a query with a placeholder for the type of animal.
db.animals.find( {type: @type} ).project( {_id:0}).sort( {name: 1} )
Running this interactively presents the following.

You can also define a Prompt component which presents a selection list with the animal types and associate the Prompt with the Data Source. The user selected value is then used for the placeholder and the query run. The variable name would be 'type' and the list options Elements formula would be
getDistinctValues("Default Data Service", "q_sample", "animals", "type")
The data source author may then associate a prompt component to present a dialog to the user when the data source is run. The entered or selected value is then used to form the effective final query. If the data source is being used in an embedded fashion, then variables can be passed in directly and no prompt component is needed. Shown below is the data source property dialog with the Prompt tab activated.
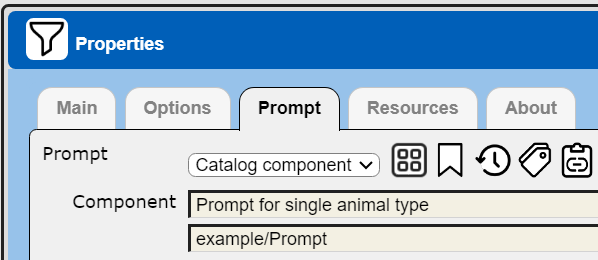
Prompts
Prompts are runtime dialogs presented to the user to gather values used for the analysis. The values obtained are typically used by data source query variables but may also be used within the analysis. For example, consider an analysis which wants to do a “what if” report which requires a sales region identifier and a churn factor. The former is used to obtain the list of customers and the latter used as a parameter to a machine learning RESTful endpoint which uses customer properties and the churn factor to predict churn likelihood.
The names of the prompt variables must be known by the referencing data source and template components. Only one prompt may be referenced. When deployed in an embedded fashion, you may set the bypassIfHaveAllValues variable to true to skip any prompt presentation when there are values for all variables defined in the prompt.
Analysis Templates
Templates may reference a prompt component by name. Shown below is the data source property dialog with the Prompt tab activated.
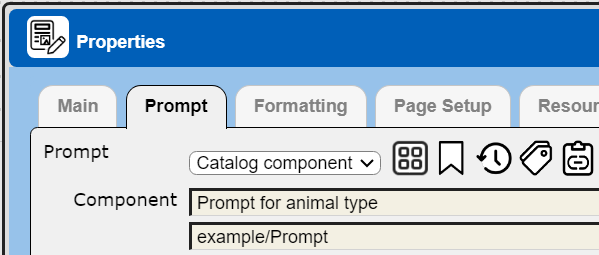
Templates can also reference multiple data source components. All templates have a main data retrieval property and each group may also perform data retrieval. What is appropriate is based on the data and type of analysis wanted. Unlike prompts though, the data retrievals can be in one of several forms:
- Reference a data source,
- Embed values for a Data Service, database, and a query, or
- Use a formula.
Option 1 is the most flexible as it reuses an existing data source component. An example is shown below.


Frequently various analyses use similar data with perhaps slightly different criteria values. As the number of templates increases, you want to keep the number of data retrieval components low. There is an implied API-like contract between these components which must be coordinated across team members. For example, a query can be updated, perhaps because of a new index, but the nature of the output should not be changed. Additional fields may be present, but the data fields should not be removed without coordination across the consuming component authors.
NOTE- From the catalog tool you may run reports to get an idea of who uses a particular component. Direct references such as a template referencing a data source will be reported. Template formulas which reference a component may not be found though given the dynamic nature of formulas. For these items you may run searches to scan component definitions.
The embedded query option number 2 does not promote any data query reusability as everything is defined inside of the template. An example is shown below.
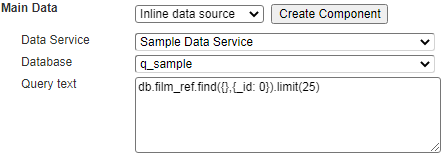
This may be simpler early on as it enables template authors to not have to explicitly define a data source for every template. However, you want to consider breaking out data retrieval queries from templates into data source components to avoid redundancy and maintenance challenges.
NOTE- From the catalog tool you may run searches to scan component definitions.You can use this functionality to locate references to a particular database collection or table.
The formula data retrieval option likely has no impact on component reuse strategy. Formulas can be used to access a document’s embedded array (i.e., @portfolio.stocks) and perform various macro language operations.